CPUs: Instruction-level parallelism ▪ Implicit ▪ Fine-grain
GPUs: Thread- & data-level parallelism ▪ Explicit ▪ Coarse-grain
Dataflow increases parallelism by eliminating unnecessary dependences

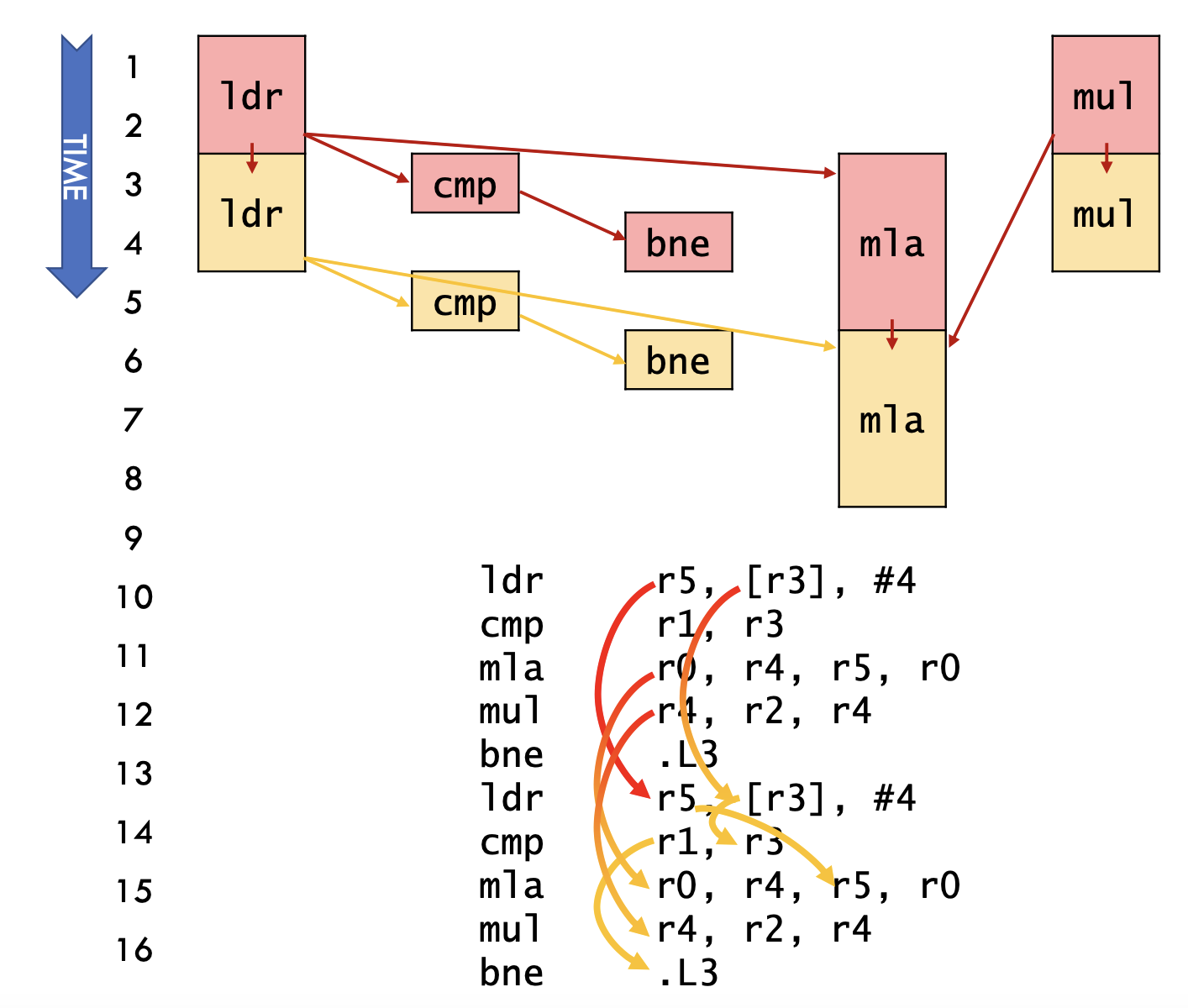
latency(critical path) bound
Longest path across iterations in dataflow graph
3 cycles/iter
OoO试图以dataflow的顺序执行程序
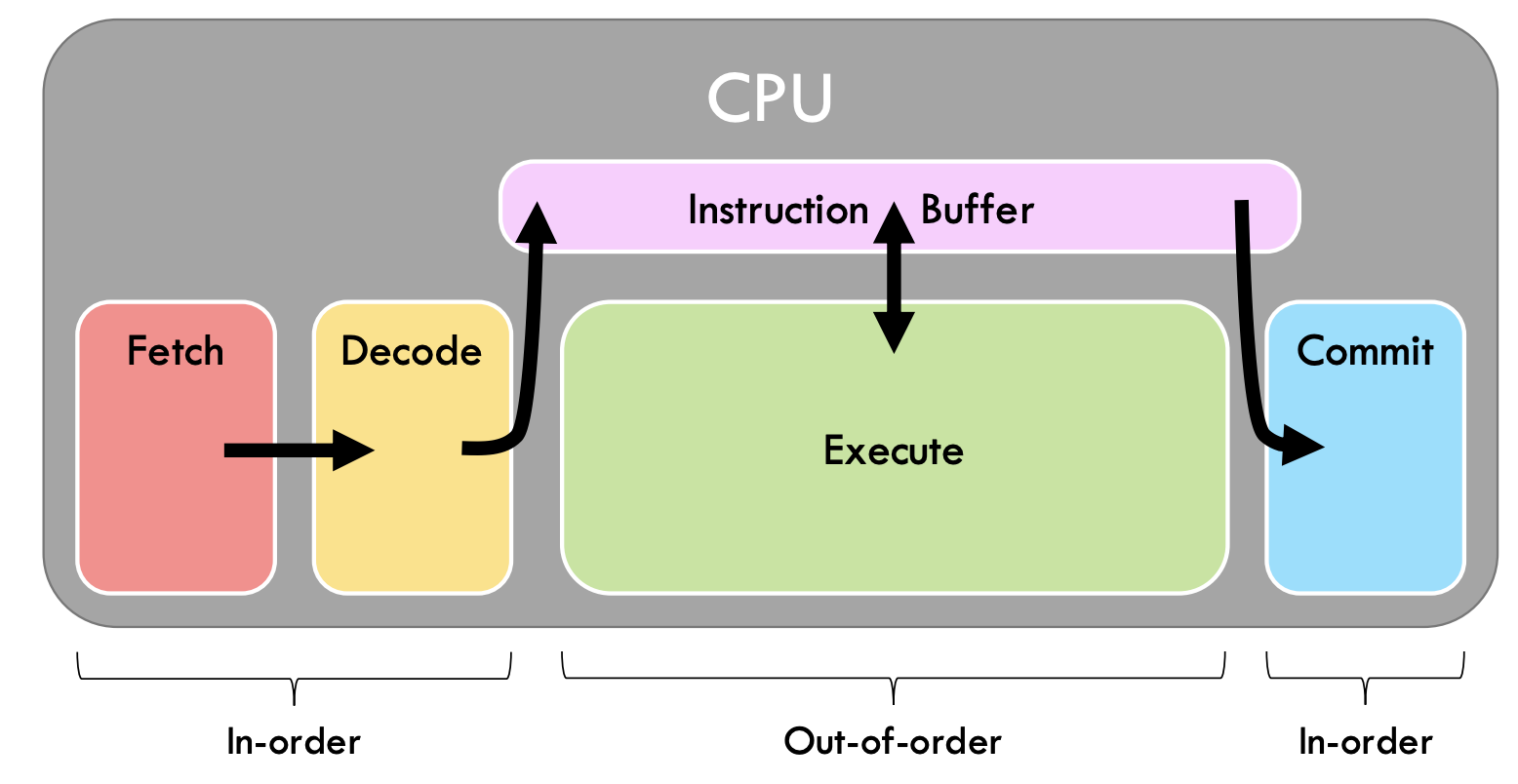
顺序取指,提交,乱序执行
naive使用OoO,会发现并没有什么提速效果
throughput bounded
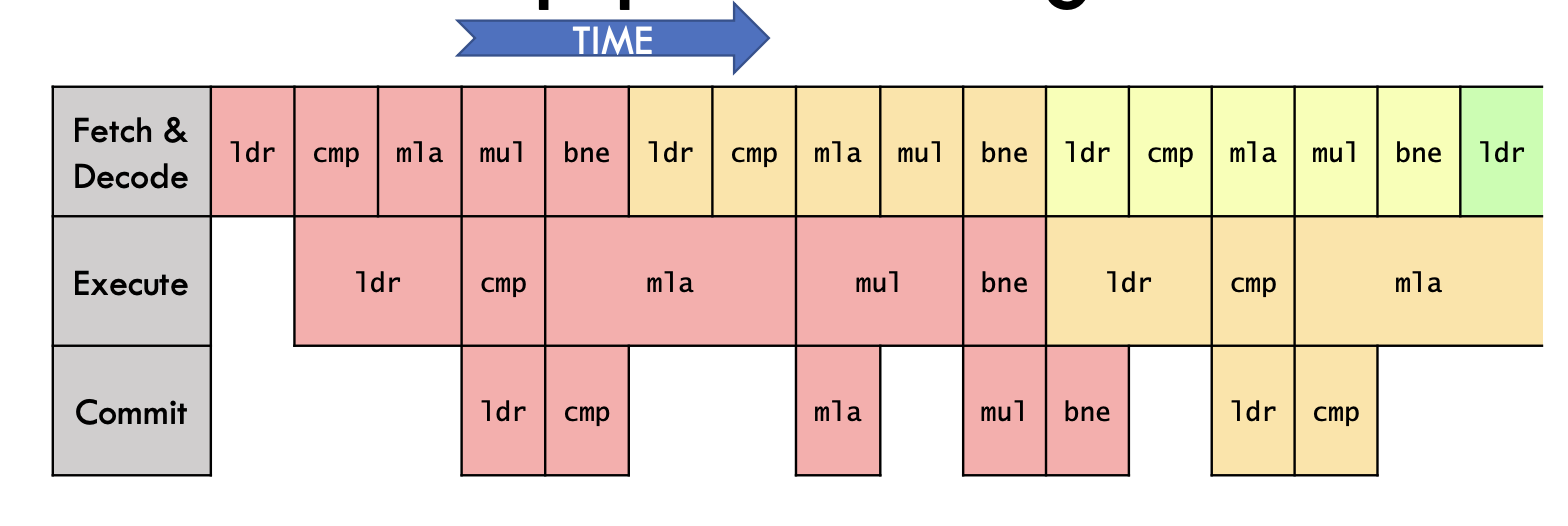
需要更多的取指单元,执行单元,提交单元并行地做,一般情况下可以认为取指单元和提交单元是over provision的
这样我们只会被latency bound
OoO对代码质量更不敏感(相对于顺序执行cpu)
throughput bound的计算方法
对于每种执行单元,计算所有该类指令个数 / issue rate
取最大值
ILP这件事情并不便于scale
关键可能和如何判定指令是否可以issue有关
也就是需要检查指令是否独立,对于issue宽度为W的处理器,检查需要W
流水线深度和issue宽度一起决定了能同时被执行的指令个数
流水线加深?
程序本身是否有ILP?
硬件多线程技术
硬件(core)能管理线程(维护多个execution context),通过切换线程执行隐藏内存访问延迟,提高吞吐量
对带宽提出高要求,因为多个线程共用cache,可能会导致更多内存访问,但是能隐藏内存访问延迟
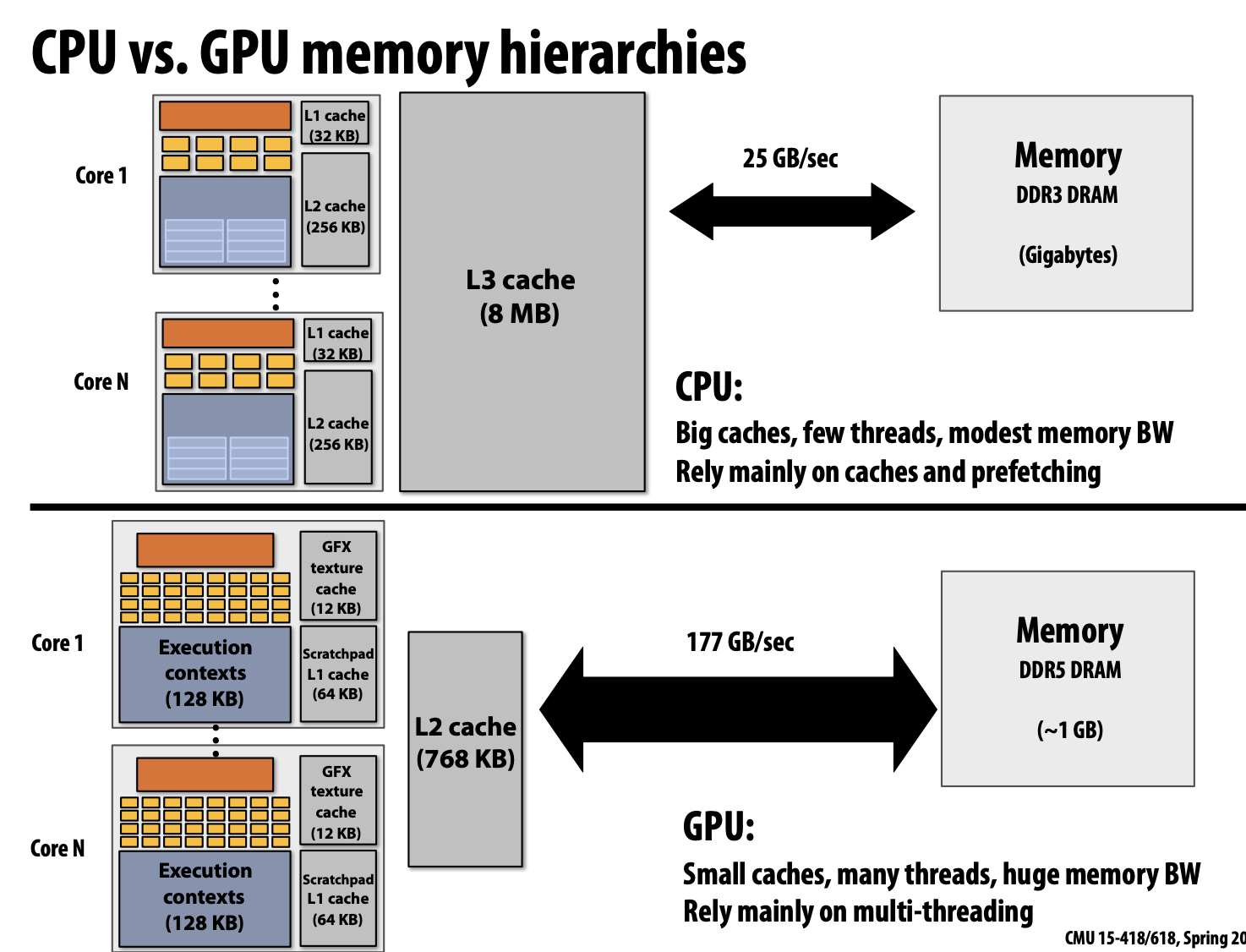
Employ multiple processing cores
- Simpler cores (embrace thread-level parallelism over instruction-level parallelism) Amortize instruction stream processing over many ALUs (SIMD)
- Increase compute capability with little extra cost Use multi-threading to make more efficient use of processing resources (hide latencies, fll all available resources)